Redis应用场景
数据缓存
热点数据的缓存。由于redis访问速度块、支持的数据类型比较丰富,所以redis很适合用来存储热点数据,另外结合expire,我们可以设置过期时间然后再进行缓存更新操作,这个功能最为常见,我们几乎所有的项目都有所运用。
会话缓存
可以使用 Redis 来统一存储多台应用服务器的会话信息。当应用服务器不再存储用户的会话信息,也就不再具有状态,一个用户可以请求任意一个应用服务器,从而更容易实现高可用性以及可伸缩性。以PHP为例,默认Session是保存在服务器的文件中,如果是集群服务,同一个用户过来可能落在不同机器上,这就会导致用户频繁登陆;采用Redis保存Session后,无论用户落在那台机器上都能够获取到对应的Session信息。
全页缓存
Redis还提供很简便的FPC平台。以Magento为例,Magento提供一个插件来使用Redis作为全页缓存后端。此外,对WordPress的用户来说,Pantheon有一个非常好的插件 wp-redis,这个插件能帮助你以最快速度加载你曾浏览过的页面。大型互联网公司都会使用Redis作为缓存存储数据,提升页面相应速度。即使重启了Redis实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降。
计数器
可以对 String 进行自增自减运算,从而实现计数器功能。Redis 这种内存型数据库的读写性能非常高,很适合存储频繁读写的计数量。由于 incrby 命令可以实现原子性的递增,所以可以运用于高并发的秒杀活动、分布式序列号的生成、具体业务还体现在比如限制一个手机号发多少条短信、一个接口一分钟限制多少请求、一个接口一天限制调用多少次等等。利用Redis中原子性的自增操作,我们可以统计类似用户点赞数、用户访问数等,这类操作如果用MySQL,频繁的读写会带来相当大的压力;限速器比较典型的使用场景是限制某个用户访问某个API的频率,常用的有抢购时,防止用户疯狂点击带来不必要的压力。
排行榜
Redis在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(Sorted Set)也使得我们在执行这些操作的时候变的非常简单在使用传统的关系型数据库(mysql、oracle等)来做这个事儿,非常的麻烦,而利用Redis的SortSet(有序集合)数据结构能够简单的搞定。
好友关系
利用集合的一些命令,比如求交集、并集、差集等。可以方便搞定一些共同好友、共同爱好之类的功能。Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。 又或者在微博应用中,每个用户关注的人存在一个集合中,就很容易实现求两个人的共同好友功能。 这个在奶茶活动中有运用,就是利用set存储用户之间的点赞关联的,另外在点赞前判断是否点赞过就利用了sismember方法,当时这个接口的响应时间控制在10毫秒内,十分高效。
消息队列(发布/订阅功能)
除了Redis自身的发布/订阅模式,我们也可以利用List来实现一个队列机制,比如:到货通知、邮件发送之类的需求,不需要高可靠,但是会带来非常大的DB压力,完全可以用List来完成异步解耦。你应该已经注意到像list push和list pop这样的Redis命令能够很方便的执行队列操作了,但能做的可不止这些:比如Redis还有list pop的变体命令,能够在列表为空时阻塞队列。现代的互联网应用大量地使用了消息队列(Messaging)。消息队列不仅被用于系统内部组件之间的通信,同时也被用于系统跟其它服务之间的交互。消息队列的使用可以增加系统的可扩展性、灵活性和用户体验。非基于消息队列的系统,其运行速度取决于系统中最慢的组件的速度(注:短板效应)。而基于消息队列可以将系统中各组件解除耦合,这样系统就不再受最慢组件的束缚,各组件可以异步运行从而得以更快的速度完成各自的工作。
延时操作
举个该特性的应用场景。 比如在订单生产后我们占用了库存,10分钟后去检验用户是够真正购买,如果没有购买将该单据设置无效,同时还原库存。 由于redis自2.8.0之后版本提供Keyspace Notifications功能,允许客户订阅Pub/Sub频道,以便以某种方式接收影响Redis数据集的事件。 所以我们对于上面的需求就可以用以下解决方案,我们在订单生产时,设置一个key,同时设置10分钟后过期, 我们在后台实现一个监听器,监听key的实效,监听到key失效时将后续逻辑加上。 当然我们也可以利用rabbitmq、activemq等消息中间件的延迟队列服务实现该需求。
分布式锁
这个主要利用redis的setnx命令进行,setnx:"set if not exists"就是如果不存在则成功设置缓存同时返回1,否则返回0 ,这个特性在俞你奔远方的后台中有所运用,因为我们服务器是集群的,定时任务可能在两台机器上都会运行,所以在定时任务中首先 通过setnx设置一个lock,如果成功设置则执行,如果没有成功设置,则表明该定时任务已执行。 当然结合具体业务,我们可以给这个lock加一个过期时间,比如说30分钟执行一次的定时任务,那么这个过期时间设置为小于30分钟的一个时间 就可以,这个与定时任务的周期以及定时任务执行消耗时间相关。
分页、模糊搜索
redis的set集合中提供了一个zrangebylex方法,如下:通过ZRANGEBYLEX zset - + LIMIT 0 10 可以进行分页数据查询,其中- +表示获取全部数据。zrangebylex key min max 这个就可以返回字典区间的数据,利用这个特性可以进行模糊查询功能,这个也是目前我在redis中发现的唯一一个支持对存储内容进行模糊查询的特性。
redis架构部署模式
大型网站应用,热点数据量往往巨大,几十G上百G是很正常的事儿。Redis是一个很好的 Cache工具。在这种情况下,如何正确架构Redis呢?
单独一台服务器的内存资源往往是有限制的,需要由多台主机协同提供服务,即分布式多个Redis实例协同运行。目前硬件资源成本降低,多核CPU,几十G内存的主机很普遍,对于主进程是单线程工作的Redis,只运行一个实例就显得有些浪费。同时,管理一个巨大内存不如管理相对较小的内存高效。因此,实际使用中,通常一台机器上同时跑多个Redis实例。
Redis 的几种常见架构模式:
- 单机部署
- 主从复制
- 哨兵模式(Sentinel)
- 高可用集群模式(Cluster)
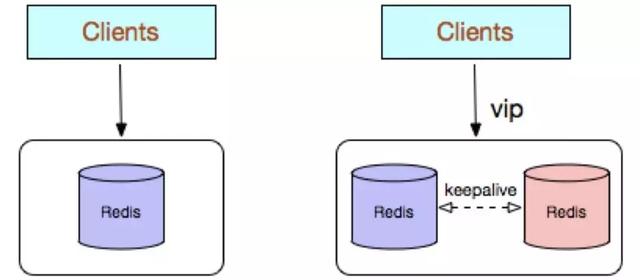
单机部署
Redis单机部署,采用单个 Redis 节点部署架构,没有备用节点实时同步数据,不提供数据持久化和备份策略,适用于数据可靠性要求不高的纯缓存业务场景。
优点:
架构简单,部署方便。高性价比:缓存使用时无需备用节点(单实例可用性可以用 supervisor 或 crontab 保证),当然为了满足业务的高可用性,也可以牺牲一个备用节点,但同时刻只有一个实例对外提供服务。
缺点:
不保证数据的可靠性。在缓存使用,进程重启后,数据丢失,即使有备用的节点解决高可用性,但是仍然不能解决缓存预热问题,因此不适用于数据可靠性要求高的业务。高性能受限于单核 CPU 的处理能力(Redis 是单线程机制),CPU 为主要瓶颈,所以适合操作命令简单,排序、计算较少的场景。也可以考虑用 Memcached 替代。
生成环境不建议使用,有单点故障风险。一旦单台结点出现故障,可能会导致整个服务不可用。
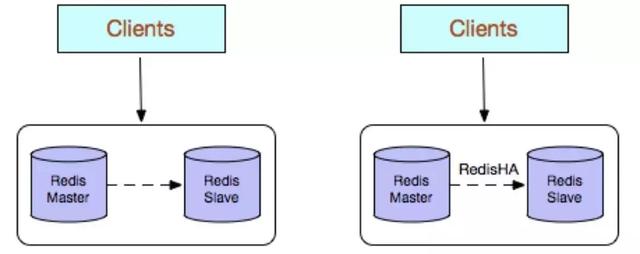
主从部署
Redis 的主从部署模式指的就是主从复制。用户可以通过 SLAVEOF 命令或者配置的方式,让一个服务器去复制另一个服务器即成为它的从服务器。 Redis 多副本,采用主从(replication)部署结构,相较于单副本而言最大的特点就是主从实例间数据实时同步,并且提供数据持久化和备份策略。主从实例部署在不同的物理服务器上,根据公司的基础环境配置,可以实现同时对外提供服务和读写分离策略。
优点:
- 高可靠性:一方面,采用双机主备架构,能够在主库出现故障时自动进行主备切换,从库提升为主库提供服务,保证服务平稳运行;另一方面,开启数据持久化功能和配置合理的备份策略,能有效的解决数据误操作和数据异常丢失的问题。
- 读写分离策略:从节点可以扩展主库节点的读能力,有效应对大并发量的读操作。
缺点:
- 故障恢复复杂,如果没有 RedisHA 系统(需要开发),当主库节点出现故障时,需要手动将一个从节点晋升为主节点,同时需要通知业务方变更配置,并且需要让其它从库节点去复制新主库节点,整个过程需要人为干预,比较繁琐。
- 主库的写能力受到单机的限制,可以考虑分片。
- 主库的存储能力受到单机的限制,可以考虑 Pika。
- 原生复制的弊端在早期的版本中也会比较突出,如:Redis 复制中断后,Slave 会发起 psync,此时如果同步不成功,则会进行全量同步,主库执行全量备份的同时可能会造成毫秒或秒级的卡顿;又由于 COW 机制,导致极端情况下的主库内存溢出,程序异常退出或宕机;主库节点生成备份文件导致服务器磁盘 IO 和 CPU(压缩)资源消耗;发送数 GB 大小的备份文件导致服务器出口带宽暴增,阻塞请求,建议升级到最新版本。
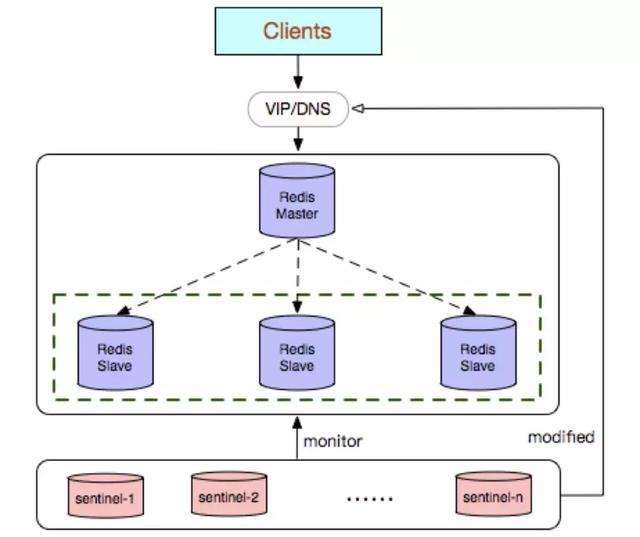
哨兵模式(Sentinel)
Redis Sentinel 是社区版本推出的原生高可用解决方案,其部署架构主要包括两部分:Redis Sentinel 集群和 Redis 数据集群。其中 Redis Sentinel 集群是由若干 Sentinel 节点组成的分布式集群,可以实现故障发现、故障自动转移、配置中心和客户端通知。Redis Sentinel 的节点数量要满足 2n+1(n>=1)的奇数个。
优点:
- Redis Sentinel 集群部署简单。
- 能够解决 Redis 主从模式下的高可用切换问题。
- 很方便实现 Redis 数据节点的线形扩展,轻松突破 Redis 自身单线程瓶颈,可极大满足 Redis 大容量或高性能的业务需求。
- 可以实现一套 Sentinel 监控一组 Redis 数据节点或多组数据节点。
缺点:
- 部署相对 Redis 主从模式要复杂一些,原理理解更繁琐。
- 资源浪费,Redis 数据节点中 slave 节点作为备份节点不提供服务。
- Redis Sentinel 主要是针对 Redis 数据节点中的主节点的高可用切换,对 Redis 的数据节点做失败判定分为主观下线和客观下线两种,对于 Redis 的从节点有对节点做主观下线操作,并不执行故障转移。
- 不能解决读写分离问题,实现起来相对复杂。
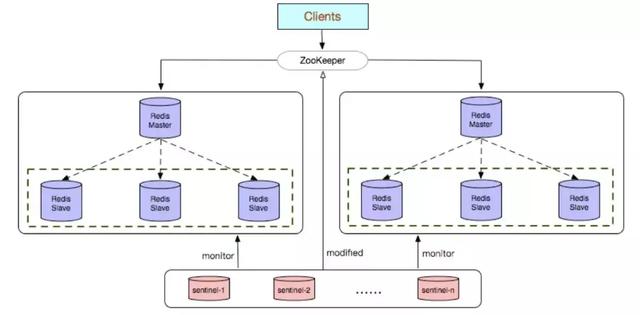
高可用集群模式(Cluster)
Redis Cluster 是社区版推出的 Redis 分布式集群解决方案,主要解决 Redis 分布式方面的需求,比如,当遇到单机内存,并发和流量等瓶颈的时候,Redis Cluster 能起到很好的负载均衡的目的。Redis Cluster 集群节点最小配置 6 个节点以上(3 主 3 从),其中主节点提供读写操作,从节点作为备用节点,不提供请求,只作为故障转移使用。Redis Cluster 采用虚拟槽分区,所有的键根据哈希函数映射到 0~16383 个整数槽内,每个节点负责维护一部分槽以及槽所印映射的键值数据。
优点:
- 无中心架构。
- 数据按照 slot 存储分布在多个节点,节点间数据共享,可动态调整数据分布。
- 可扩展性:可线性扩展到 1000 多个节点,节点可动态添加或删除。
- 高可用性:部分节点不可用时,集群仍可用。通过增加 Slave 做 standby 数据副本,能够实现故障自动 failover,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave 到 Master 的角色提升。
- 降低运维成本,提高系统的扩展性和可用性。
缺点:
- Client 实现复杂,驱动要求实现 Smart Client,缓存 slots mapping 信息并及时更新,提高了开发难度,客户端的不成熟影响业务的稳定性。目前仅 JedisCluster 相对成熟,异常处理部分还不完善,比如常见的“max redirect exception”。
- 节点会因为某些原因发生阻塞(阻塞时间大于 clutser-node-timeout),被判断下线,这种 failover 是没有必要的。
- 数据通过异步复制,不保证数据的强一致性。
- 多个业务使用同一套集群时,无法根据统计区分冷热数据,资源隔离性较差,容易出现相互影响的情况。
- Slave 在集群中充当“冷备”,不能缓解读压力,当然可以通过 SDK 的合理设计来提高 Slave 资源的利用率。
- Key 批量操作限制,如使用 mset、mget 目前只支持具有相同 slot 值的 Key 执行批量操作。对于映射为不同 slot 值的 Key 由于 Keys 不支持跨 slot 查询,所以执行 mset、mget、sunion 等操作支持不友好。
- Key 事务操作支持有限,只支持多 key 在同一节点上的事务操作,当多个 Key 分布于不同的节点上时无法使用事务功能。
- Key 作为数据分区的最小粒度,不能将一个很大的键值对象如 hash、list 等映射到不同的节点。
- 不支持多数据库空间,单机下的 redis 可以支持到 16 个数据库,集群模式下只能使用 1 个数据库空间,即 db 0。
- 复制结构只支持一层,从节点只能复制主节点,不支持嵌套树状复制结构。
- 避免产生 hot-key,导致主库节点成为系统的短板。
- 避免产生 big-key,导致网卡撑爆、慢查询等。
- 重试时间应该大于 cluster-node-time 时间。
- Redis Cluster 不建议使用 pipeline 和 multi-keys 操作,减少 max redirect 产生的场景。